A sample text widget
Etiam pulvinar consectetur dolor sed malesuada. Ut convallis
euismod dolor nec pretium. Nunc ut tristique massa.
Nam sodales mi vitae dolor ullamcorper et vulputate enim accumsan.
Morbi orci magna, tincidunt vitae molestie nec, molestie at mi. Nulla nulla lorem,
suscipit in posuere in, interdum non magna.
|
 LINGUATEC project: Development of cross-border cooperation and knowledge transfer in language technologies.
LINGUATEC is an European project funded by FEDER via POCTEFA (Programa INTERREG V-A España-Francia-Andorra). The partners are the followings:
- Elhuyar Fundazioa
- Lo Congrès Permanent de la Lenga Occitana
- Universidad Del País Vasco / Euskal Herriko Unibertsitatea (Ixa Taldea)
- CNRS (CENTRE National de la Recherche Scientifique) – Delegation Regionale Midi-Pyrenees
- Euskaltzaindia – Real Academia de la Lengua Vasca
- Sociedad De Promoción y Gestión del Turismo Aragonés
The main objective in Linguatec is to develop, test and disseminate new innovative linguistic resources, tools and solutions for a better digitalization level of the Aragonian, Basque and Occitan languages. As a result, we will obtain, among others, (1) a road map of Aragonian Digitalization, (2) new monolingual and bilingual lexicons and morphosyntactic and syntactic analysers for Occitan, (3) a Northern Basque speech recognition system and several linguistic tools as well as (4) new innovative solutions for Aragonian, Basque and Occitan.
These cross-border cooperation will allow the transfer of knowledge and to develop linguistic solutions with a potential market uptake, benefiting language professionals, easing access to multilingual contents, and fostering the development of a cross-border language tech cluster.
After one year work, last Wednesday we had a project meeting in Donostia organized by Euskaltzaindia. Ixa Group presented the progress in the creation of an improved Neuronal Machine Translation system for the pair Spanish-Basque.
 

Last week our colleagues Mikel Artetxe, Gorka Labaka, Iñigo Lopez-Gazpio, and Eneko Agirre were the recipients of the Best Paper Award in the 22nd Conference on Computational Natural Language Learning (CoNLL 2018) for the paper “Uncovering Divergent Linguistic Information in Word Embeddings with Lessons for Intrinsic and Extrinsic Evaluation”.
Congratulations!

.
.
.
.
Abstract:
Following the recent success of word embeddings, it has been argued that there is no such thing as an ideal representation for words, as different models tend to capture divergent and often mutually incompatible aspects like semantics/syntax and similarity/relatedness. In this paper, we show that each embedding model captures more information than directly apparent. A linear transformation that adjusts the similarity order of the model without any external resource can tailor it to achieve better results in those aspects, providing a new perspective on how embeddings encode divergent linguistic information. In addition, we explore the relation between intrinsic and extrinsic evaluation, as the effect of our transformations in downstream tasks is higher for unsupervised systems than for supervised ones.
UncoVec:
This is an open source implementation in GitHub of our word embedding post-processing and evaluation framework, described in the paper.
When: Thursday, 8 November
12:00 – 1:00pm
Description: Neural networks have led to previously unimaginable advances in NLP engineering tasks. The main criticism against them from a linguistic point of view is that neural models – while fine for “language engineering tasks” – are thought of as being black boxes, and that their parameter opacity prevents us from discovering new facts about the nature of language itself, or specific languages. In this talk I will challenge that assumption to show that there are ways to uncover facts about language, even with a black box learner. I will discuss specific experiments with neural models and sound embeddings that reveal new information about the organization of sound systems in human languages (phonology), give us insight into the complexity of word-formation (morphology), give us models of why and when irregular forms – surely an inefficiency in a communication system – can persist over long periods of time (historical linguistics), and reveal what the boundaries of pattern learning is (how much information do we minimally need to learn a grammatical aspect of language such as its word inflection or sentence formation).
Last September Aitor Gonzalez Agirre was awarded with the best MSc thesis Award 2018 by the SEPLN association. Congratulations to Aitor and to his supervisors Eneko Agirre and German Rigau.

Aitor is now working at the Barcelona Supercomputing Center.
The abstract of his thesis entitled “Computational Models for Semantic Textual Similarity” is the following:
Measuring semantic similarity between textual items (words, sentences, paragraphs or even documents) is a very important research area in Natural Language Processing (NLP). It has many practical applications in other NLP tasks such as Word Sense Disambiguation, Textual Entailment, Paraphrase detection, Machine Translation, Summarization, Information Retrieval or Question Answering.
The overarching goal of this thesis is to advance on computational models of meaning and their evaluation. To achieve this goal we define two tasks and develop state-of-the-art systems that tackle both tasks: Semantic Textual Similarity (STS) and Typed Similarity.
STS aims to measure the degree of semantic equivalence between two sentences by assigning graded similarity values. This graded similarity captures the notion of intermediate shades of similarity ranging from pairs of text that differ only in minor nuanced aspects of meaning, in relatively important differences,
down to pairs that share only some details or that only have in common being about the same topic. In the scope of this research, we have collected pairs of sentences to construct datasets for STS, a total of 15,436 pairs of sentences, being by far the largest collection of data for STS.
Using these new datasets for STS we have designed, constructed and evaluated a new approach to combine knowledge-based and corpus-based methods using a cube. This new system for STS is on par with state-of-the-art approaches that make use of Machine Learning (ML) without using any of it, but ML can be used
on this system, improving the results.
Typed Similarity tries to identify the type of relation that holds between a pair of similar items in a digital library. Being able to provide a reason why items are similar has applications in recommendation, personalization, and search. We investigate the problem within the context of Europeana, a large digital library containing items related to cultural heritage. A range of types of similarity in this collection were identified and a set of 1,500 pairs of items from the collection were annotated using crowdsourcing.
Finally, we present three systems capable of resolving the Typed Similarity task: a baseline approach, a knowledge-based approach and a ML system. The high results obtained by our systems suggests that this technology is close to practical applications. In fact, the system based on ML resulted in a real-world application to recommend similar items to users in an online digital library.
[ES]
En la XVII Edición de los premios SEPLN a la mejor tesis doctoral en Procesamiento del Lenguaje Natural se han presentado doce trabajos de gran calidad. Cada monografía ha sido evaluada por tres revisores. Destacar el alto nivel científico y técnico, siendo todas ellas merecedoras del premio. Finalmente, ha quedado mejor valorada, y por consiguiente, premiada y propuesta para su publicación electrónica la titulada “Computational Models for Semantic Textual Similarity” de Aitor González Agirre, como el décimoséptimo número de esta serie de publicaciones.
This week, the report on Language Equality in the Digital Age that was presented by Jill Evans MEP of Wales was overwhelmingly endorsed by the European Parliament with 592 MEPs voting in favour, and with only 45 against and 44 abstentions. Find here a link to a press release about the vote: https://www.greens-efa.eu/en/article/press/victory-for-language-equality-in-the-european-parliament/
CONGRATULATIONS!
https://youtu.be/MqRBloVr5N4
 The report endorsed by EuroParl It is not a law, but it is a declaration made by the European Parliament, which can be a guiding reference for all countries. Today, as until now there were no laws or declarations of the European Parliament to protect the low resourced languages, everything remains in the hands of the local legislation of each country, which could without problems ignore these languages. It is not a law, but this Europarl report is a step forward.
Jill Evans MEP said:
- “I am pleased that the European Parliament agrees with my view that action needs to be taken to address the digital gap between European languages.
- “European citizens must be able to access and use the digital world in their own languages, including in minority languages. This will require investment and leadership at the EU level.
- “This is a huge opportunity for the EU to demonstrate a real commitment to language equality, for the speakers of all of Europe’s languages, including Welsh.”
The report calls on the EU to:
- improve the institutional frameworks for language technology policies,
- create new research policies to increase the use of language technology in Europe,
- use education policies in order to secure the future of language equality in the digital age,
- increase the support for both private companies and public bodies to make better use of language technologies.
 Last January, Maite Melero representing Catalan, Delith Prys representing Welsh, and Iñaki Irazabalbeitia and Kepa Sarasola representing Basque participated in the creation of the first draft of the report. Last January, Maite Melero representing Catalan, Delith Prys representing Welsh, and Iñaki Irazabalbeitia and Kepa Sarasola representing Basque participated in the creation of the first draft of the report.
A conference with the same title Language equality in the digital age will be held on september 27th in the European Parliament to show to the MEPs the opportunities this technology is offering to European languages. Jill Evans, Maite Melero, Delith Prys and our colleague Montse Maritxalar from Ixa Group are going to participate. (See here the schedule)
 Four master theses have been presented in June: Four master theses have been presented in June:
15:00
Noisy Speech Recognition using Kaldi and Neural Architectures
Ikaslea/Student: Ander González Docasal
Zuzendariak/Supervisors: Vassilis Tsiaras, George P. Kafentzis, Yannis Stylianou
15:45
Unsupervised Methods to Predict Example Difficulty in Word Sense Annotation
Ikaslea/Student: Cristina Aceta Moreno
Zuzendariak/Supervisors: Oier Lopez de Lacalle, Eneko Agirre, Izaskun Aldezabal
16:30
To post‐edit or to translate… That is the question.
A case study of a recommender system for Quality Estimation of Machine Translation based on linguistic feature
Ikaslea/Student: Ona de Gilbert Bonet
Zuzendaria/Supervisor: Nora Aranberri
17:15
Basque‐to‐Spanish and Spanish‐to‐Basque Machine Translation for the health domain
Ikaslea/Student: Xabier Soto García
Zuzendariak/Supervisors: Gorka Labaka, Olatz Perez de Viñaspre
Zuzendarikidea/Co‐advisor: Maite Oronoz
 Speaker: Ilia Moshnikov Speaker: Ilia Moshnikov
…………Karelian Institute (Joensuu)
Date: Tuesday,June 19, 2018
Time: 15:00-16:00
Place: UPV/EHUko Informatika Fakultatea, Manuel de Lardizabal 1, 20018 Donostia (map)
Title: Variants of the active past participle in the Border Karelian dialects:
how to study variation between closely related languages?
Abstract:
During my visit I would like to present my research interests. I will speak about my home university in general. I will say a few words about current situation of the Karelian language and usage of it in Internet. During my work in Kiännä-research project I investigated from a virtual linguistic landscape point of view what websites use Karelian as a language of full interface. I will also talk about my doctoral dissertation. Topic of my presentation is Variants of the active past participle in the Border Karelian dialects: how to study variation between closely related languages? I use some statistical methods. Theoretically my background is in language contacts and language variation research.
Short bio:
My name is Ilia Moshnikov and I am a visiting researcher from University of Eastern Finland (Joensuu, Finland). I will stay in San Sebastian one month. I am a linguist and my doctoral dissertation is about language contacts between Finnish and Karelian languages in Border Karelian dialects. Moreover, some of my interests are language revitalization and modern language usage. For example, I am involved in Karelian Wikipedia. Originally, I am from Russian Karelia. I speak Karelian, Finnish, English and Russian (a bit Spanish as well). I work as a researcher in Karelian Institute (Joensuu) and teach some Karelian (and Russian) courses.
 Speaker: Francis Bond. Speaker: Francis Bond.
…………Division of Linguistics and Multilingual Studies,
…………Nanyang Technological University. Singapore
Date: June 13, 2018
Time: 15:00
Place: UPV/EHUko Informatika Fakultatea, Manuel de Lardizabal 1, 20018 Donostia (map)
Title: The Open Multilingual Wordnet
Abstract:
In this talk I introduce the Open Multilingual Wordnet, a large lexical network of words grouped into concepts and linked by typed semantic relations. The talk will cover how the resource has evolved over time (increases in both size and complexity) and introduce some of the latest extensions.
Short bio:
Francis Bond is an Associate Professor at the Division of Linguistics and Multilingual Studies, Nanyang Technological University, Singapore. He worked on machine translation and natural language understanding in Japan, first at Nippon Telegraph and Telephone Corporation and then at the National Institute of Information and Communications Technology, where his focus was on open source natural language processing. He isan active member of the Deep Linguistic Processing with HPSG Initiative (DELPH-IN) and the Global WordNet Association. His main research interest is in natural language understanding. Francis has developed and released wordnets for Chinese, Japanese, Malay and Indonesian and coordinates the open multilingual wordnet.
[EN]
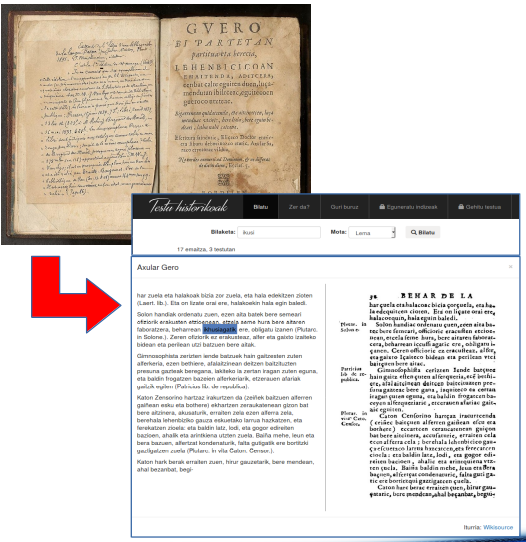 The collection, tagging, analysis and recovery of historical corpora are basic tasks in the quantitative research on linguistic and cultural evolution. Collaboration between the areas of linguistics, history and technology is necessary for the success of these processes. The collection, tagging, analysis and recovery of historical corpora are basic tasks in the quantitative research on linguistic and cultural evolution. Collaboration between the areas of linguistics, history and technology is necessary for the success of these processes.
Several international projects are being carried out in this field and some of these experiences will be presented at this workshop. In the Basque Country there are also projects in progress but in an atomized manner.
Date: June 11th. 11.00 a.m. (Ada Lovelace hall)
Place: Informatics Faculty UPV/EHU. Manuel Lardizabal 1, 20018 Donostia (map)
Language: English
Program:
11.00-11.30: Ricardo Etxepare: BIM project, Basque in the making (Sintaktikoki Etiketatutako Euskarazko Corpus Historikoa)
11.30-12.15: Martin Reynaert: Text-Induced Corpus Clean-up: current state-of-the-art
12.15-13.00: Eckhard Bick: Automatic Grammatical Annotation of Historical Brazilian Portuguese
Sponsors: UPPA – UPV/EHU – Clarin
   
[ES]
PROCESADO DE CORPUS HISTÓRICOS
Jornada abierta. 11 de Junio.
La recopilación, etiquetado, análisis y consulta de corpus históricos son tareas fundamentales en la investigación cuantitativa de la evolución lingüística y cultural. La colaboración entre las áreas de lingüística, historia y tecnología es necesaria para el éxito de los procesos mencionados.
Diversos proyectos internacionales se están llevando a cabo en este ámbito y en esta jornada se expondrán algunas de estas experiencias. En Euskal Herria también hay proyectos en marcha pero de forma atomizada.
Fecha: 11 de junio de 2018, 11.00. (Sala Ada Lovelace)
Lugar: Facultad de Informática UPV/EHU. Manuel Lardizabal 1, 20018 Donostia (mapa)
Idioma: inglés
Programa:
11.00-11.30: Ricardo Etxepare: BIM project, Basque in the making (Sintaktikoki Etiketatutako Euskarazko Corpus Historikoa)
11.30-12.15: Martin Reynaert: Text-Induced Corpus Clean-up: current state-of-the-art
12.15-13.00: Eckhard Bick: Automatic Grammatical Annotation of Historical Brazilian Portuguese
Patrocinadores: UPPA – UPV/EHU – Clarin
|
|

 Date: February 25th
Date: February 25th
 Speaker:
Speaker: