A sample text widget
Etiam pulvinar consectetur dolor sed malesuada. Ut convallis
euismod dolor nec pretium. Nunc ut tristique massa.
Nam sodales mi vitae dolor ullamcorper et vulputate enim accumsan.
Morbi orci magna, tincidunt vitae molestie nec, molestie at mi. Nulla nulla lorem,
suscipit in posuere in, interdum non magna.
|
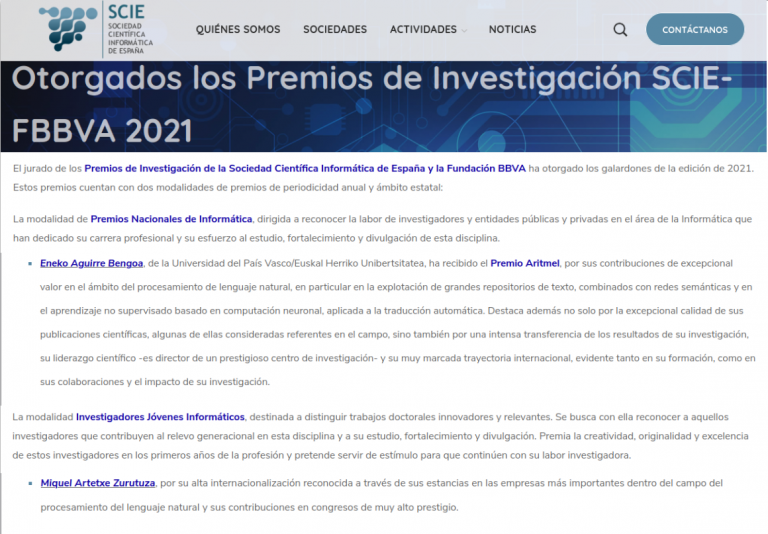
The members of Ixa Group Eneko Agirre and Mikel Artetxe have received two spanish leading SCIE awards of 2021. Eneko has received the National Award on Informatics and Mikel has been one of the six awards for young researchers.

The jury explained that Eneko Agirre has been awarded for his excellent contributions in the field of Natural Language Processing, especially in the exploitation of large textual resources and also in unsupervised machine learning based on neuronal computing applied to machine translation. In addition to the excellent quality of his scientific publications (some of them considered to be global references), the jury remarked the great transfer of research results, his scientific leadership (Head of the HiTZ research center), and his international trajectory, both in training and collaborations.
 For Mikel Artetxe has been one of the six Computer Awards for Young Researchers. The jury highly valued Mikel for his his wide international presence, his stays in the main companies in the field of language processing and his contributions to prestigious congresses. For Mikel Artetxe has been one of the six Computer Awards for Young Researchers. The jury highly valued Mikel for his his wide international presence, his stays in the main companies in the field of language processing and his contributions to prestigious congresses.
Zorionak! Congratulations to Eneko and Mikel!

The European project EFA 227/16/LINGUATEC “Development of cross-border cooperation and knowledge transfer in language technologies” organizes the workshop open to all researchers, with the aim of disseminating the work carried out within the project and presenting some of the advances made for Basque and Occitan.
This project is co-financed by the European Regional Development Fund (ERDF)
Free registration. Please, use this registration form
12 May, 2021
Online, with presentations in English, Spanish and French, with simultaneous translation into English, Spanish and French.
10h – Opening
10h15 Invited talks: Catalan processing
Lluis Padró (Universitat Politècnica de Catalunya)
Morphological and Syntactic Resources in FreeLing
Presentation in English – Simultaneous translation in Spanish and French
Mariona Taulé (Universitat de Barcelona)
AnCora: un corpus anotado a diferentes niveles lingüístico
AnCora: a corpus annotated at different linguistic levels
Presentation in Spanish – Simultaneous translation in English and French
11h15 — Break

11h30 Presentations: Corpora for Occitan, Basque and other under-resourced languages
Assaf Urieli, Joliciel
Talismane, Jochre: automatic syntax analysis and OCR for under-resourced languages
Presentation in English – Simultaneous translation in Spanish and French
Aleksandra Miletic y Dejan Stosic, CLLE
Mutualisation des ressources pour la création de treebanks : le cas du serbe et de l’occitan
Pooling resources for the creation of syntactic tree banks: the case of Serbian and Occitan
Presentation in French – Simultaneous translation in English and Spanish
Ainara Estarrona (IXA, HiTZ, UPV/EHU)
Construcción del corpus histórico en euskera
Construction of a historical corpus in Basque
Presentation in Spanish – Simultaneous translation in English and French
13h — Break
14h30 Invited talk: Use of Neural Networks
Mans Hulden (University of Colorado)
Neural Networks in Linguistic Research
Presentation in English – Simultaneous translation in Spanish and French
15h30 Presentación: Language processing
Rodrigo Agerri (IXA, HITZ, UPV/EHU)
Contextual lemmatization for inflected languages: statistical and deep-learning approaches
Presentation in English – Simultaneous translation in Spanish and French
16h – Break
16h15 – Presentations: Results of the LINGUATEC project
Myriam Bras, Aleksandra Miletic, Marianne Vergez-Couret, Clamença Poujade, Jean Sibille, Louise Esher, CLLE :
Automatic processing of Occitan: construction of the first annotated corpora
Video in Occitan with accessible subtitles in English, Spanish and French
Elhuyar
Creation and improvement of Basque resources within the framework of Linguatec
Video in Occitan with accessible subtitles in English, Spanish and French
16h45 – Conclusions
Presentation in Spanish and French – No simultaneous translation
17h – Closing
 Jokin Bildarratz, Education Chancellor in Basque Government Last week we presented the new HiTZ Research Center.
Along with director Eneko Agirre in the presentation were present Rector Nekane Balluerka, Education Chancellor in the Basque Government Jokin Bildarratz, Deputy General of Gipuzkoa Markel Olano and Mayor of Saint Sebastian Eneko Goia.
 Eneko Agirre, Director of HiTZ Center We have created HiTZ Center by merging two research groups: IXA and Aholab. The research groups Ixa and Aholab, both from the University of the Basque Country (UPV/EHU), have been — since their creation in 1988 and 1998 respectively — the main tractors in the area of Language Technologies of the Basque Country. Both groups have been collaborating since 2002, when they promoted the formation of an Basque consortium in strategic research after contacting and attracting to the area the Elhuyar Foundation and the Vicomtech-IK4T and Tecnalia technology centers (named Robotiker at the time). Since then, the consortium has maintained an uninterrupted line of collaboration within the strategic projects of the Basque Government as well as local and state calls for proposals.
Now we are a total of 60 members (professors, researchers, technicians and PhD students), a broad team with interdisciplinary experts: computer scientists, linguists, engineers, translators and sociologists, among others.

By bringing together what the two groups separately did in training, research and technological transfer, this new research center aims to be an international reference in Language Technology.
The IXA Group has a history of 32 years in the treatment of written contents.
The Aholab Group has been working since 1998 in speech technology.
We have been collaborating since 2002

We are an important research and development center worldwide together with other agents related to artificial intelligence, and we currently work on 36 research projects, six of them in Europe and the United States. In the last year we published our research results in 78 scientific articles.

As for training, we offer the Erasmus Mundus International Master’s Degree, a doctoral programme in linguistic technologies and an international course on “Deep Learning” techniques. In the newly created Degree in Artificial Intelligence at the Faculty of Informatics of San Sebastian we also have an important role.


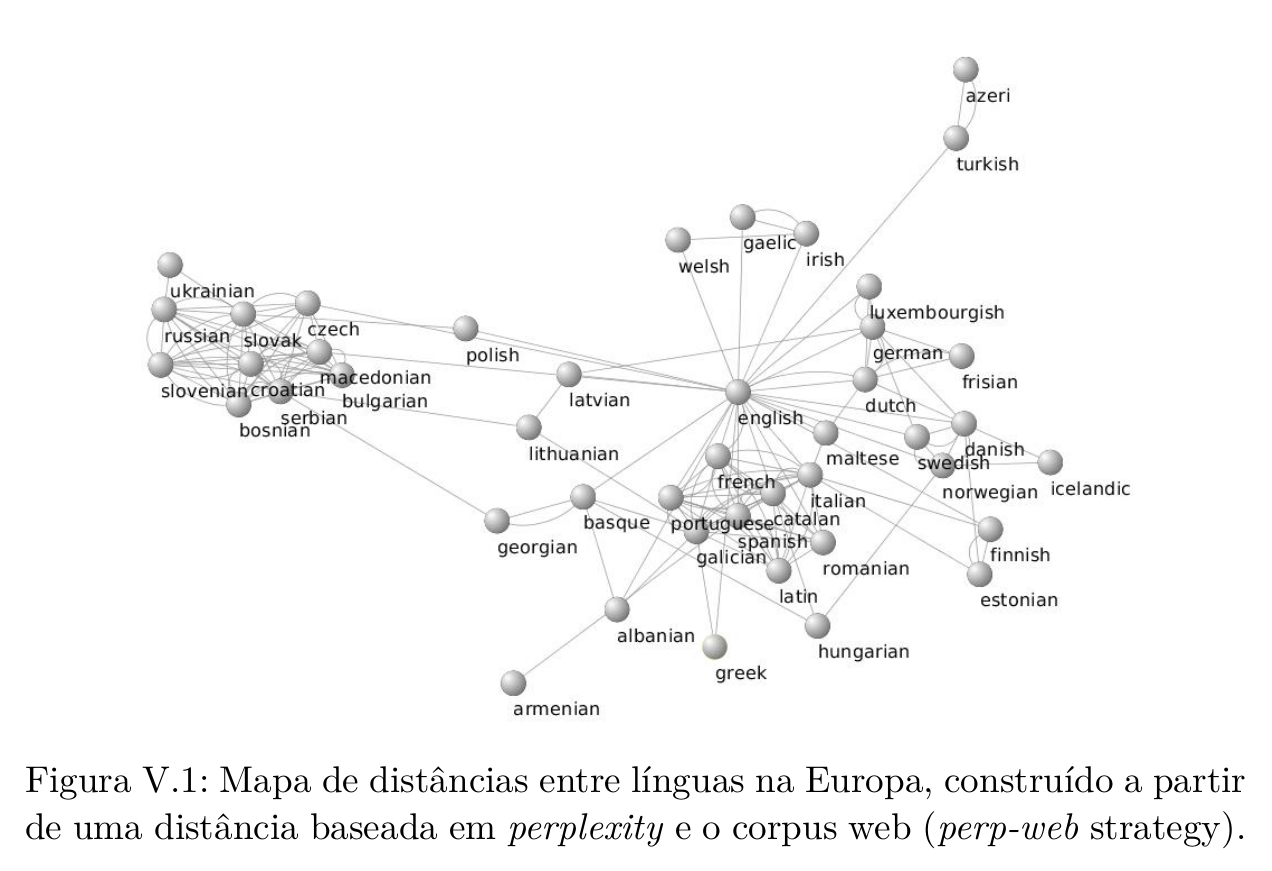
 Title: Medidas de distância entre línguas baseadas em corpus. Aplicação à linguística histórica do galego, poruguês, espanhol e inglês Title: Medidas de distância entre línguas baseadas em corpus. Aplicação à linguística histórica do galego, poruguês, espanhol e inglês
/ Corpus based metrics for measuring distances between languages. Application to historical linguistics of Galician, Portuguese, Spanish and English.
Where: Teleconference,
……….https://eu.bbcollab.com/guest/5b757d040d024f7b91deaaaffe3bec03
……….Faculty of informatics (UPV/EHU) Ada Lovelace room
Date: October 29, 2020, Thursday, 18:30
Author: José Ramom Pichel
Supervisors: Iñaki Alegria & Pablo Gamallo
Languages: Portuguese, mainly
Abstract:
As dúvidas sobre a classificação filogenética histórica e actual do galego e as hesitações na identificação au-
tomática da língua e na construção e concepção de tradutores automáticos, sugerem que o cálculo automático da distância entre o galego, o português e o espanhol, a partir de textos escritos reais, e um desafio interessante.
1. Pode a distância entre línguas ser medida automaticamente com base em corpus?
2. Que papel desempenha a ortografia na distância entre as línguas?
3. É possível traduzir esta distância numa única métrica robusta?
4. A distância calculada com essa métrica verifica as hipóteses dos linguistas?
Adiciona novos dados sobre hipóteses minoritárias ou controversas?
5. Será que a distância entre períodos históricos da mesma língua muda? Como?
6. A distância entre línguas muda historicamente ou é sempre a mesma?
E se mudar, esta distância entre línguas é linear?
7. Será que a distância histórica entre variantes reconhecidas da mesma língua muda?
Related publications to his PhD work:
Good news for languages with few resources!
Pre-trained Basque monolingual and multilingual language models have proven to be very useful in NLP tasks for Basque!
Even they have been created with a 500 times smaller corpus than the English one and with a 80 times smaller wikipedia.
 An example of Conversational Question Answering, and its transcription to English. Word embeddings and pre-trained language models allow to build rich representations of text and have enabled improvements across
most NLP tasks. Unfortunately they are very expensive to train, and many small companies and research groups tend to use models that have been pre-trained and made available by third parties, rather than building their own. This is suboptimal as, for many languages, the models have been trained on smaller (or lower quality) corpora. In addition, monolingual pre-trained models for non-English languages are not always available. At best, models for those languages are included in multilingual versions, where each language shares the quota of substrings and parameters with the rest of the languages. This is particularly true for smaller languages such as Basque.
Last April we show that a number of monolingual models (FastText word embeddings, FLAIR and BERT language models) trained with larger Basque corpora (crawled news articles from online newspapers) produced much better results than publicly available versions in downstream NLP tasks, including topic classification, sentiment classification, PoS tagging and NER. this work was presented in the paper entitled “Give your Text Representation Models some Love: the Case for Basque“. The composition of the Basque Media Corpus (BMC) used in that experiment was as follows:
| Source |
Text type |
Million tokens |
| Basque Wikipedia |
Enciclopedia |
35M |
| Berria newspaper |
News |
81M |
| EiTB |
News |
28M |
| Argia magazine |
News |
16M |
| Local news sites |
News |
224.6M |
Take into account that the original BERT language model for English was trained using Google books corpus that contains 155 billion words in American English, 34 billion words in British English. The English corpus is almost 500 times bigger than the Basque one.
 Agerri 
San Vicente
 Campos  Otegi  Barrena  Saralegi  Soroa  E. Agirre  An example of a dialogue where there are many references in the questions to previous answers in the dialogue.

Now, in September we have published IXAmBERT, a multilingual language model pretrained for English, Spanish and Basque. And we have successfully experimented with it in a Basque Conversational Question Answering system. This transfer experiments could be already performed with Google’s official mBERT model, but as it covers that many languages, Basque is not very well represented. In order to create this new multilingual model that contains just English, Spanish and Basque, we have followed the same configuration as in the BERTeus model presented in April. We re-use the same corpus of the monolingual Basque model and add the English and Spanish Wikipedia with 2.5G and 650M tokens respectively. The size of these wikipedias is 80 and 20 times bigger than the Basque one.
The good news is that this model has been successfully used to transfer knowledge from English to Basque in a conversational Question/Answering system, as reported in the paper Conversational Question Answering in Low Resource Scenarios: A Dataset and Case Study for Basque. In the paper, the new language model called IXAmBERT performed better than mBERT when transferring knowledge from English to Basque, as shown in the following table:
| Model |
Zero-shot |
Transfer learning |
| Baseline |
28.7 |
28.7 |
| mBERT |
31.5 |
37.4 |
| IXAmBERT |
38.9 |
41.2 |
| mBERT + history |
33.3 |
28.7 |
| IXAmBERT + history |
40.7 |
40.0 |
This table shows the results on a Basque Conversational Question Answering (CQA) dataset. Zero-shot means that the model is fine-tuned using using QuaC, an English CQA dataset. In the Transfer Learning setting the model is first fine-tuned on QuaC, and then on a Basque CQA dataset.
These works set a new state-of-the-art in those tasks for Basque.
All benchmarks and models used in this work are publicly available: https://huggingface.co/ixa-ehu/ixambert-base-cased

This summer we have created AI Basque with the GAIA cluster. We want to achieve greater diffusion in our local area for the work that our HITZ Center carries out in language technology and artificial intelligence.
 Basque Cluster on ‘Knowledge and Applied Technology Industry’ With AI Basque center we want to be an international reference in the field of artificial intelligence (AI), in industry, services sector and public administration. Our goal is to make companies, institutions and citizens aware of the advantages of artificial intelligence and proper data management. We want to extend this effort to all economic and social areas, in collaboration with other sectors, promoting the development of new products and services.
Who are we in AI Basque at present:
- 21 companies in the sector of ‘Knowledge and Applied Technology Industry’
- 3 technology centers
- Gaia Cluster
- and our Hitz Center of the UPV/EHU.
See news published by GAIA Cluster:
Nace AI BASQUE de la mano del Clúster GAIA y del Grupo Hitz de la UPV-EHU para impulsar la Inteligencia Artificial en Euskadi
and by the Basque Government:
AI Basque sortu da, Gaia Klusterraren eta EHUko Hitz Taldearen eskutik, Inteligentzia Artifiziala sustatzeko Euskadin

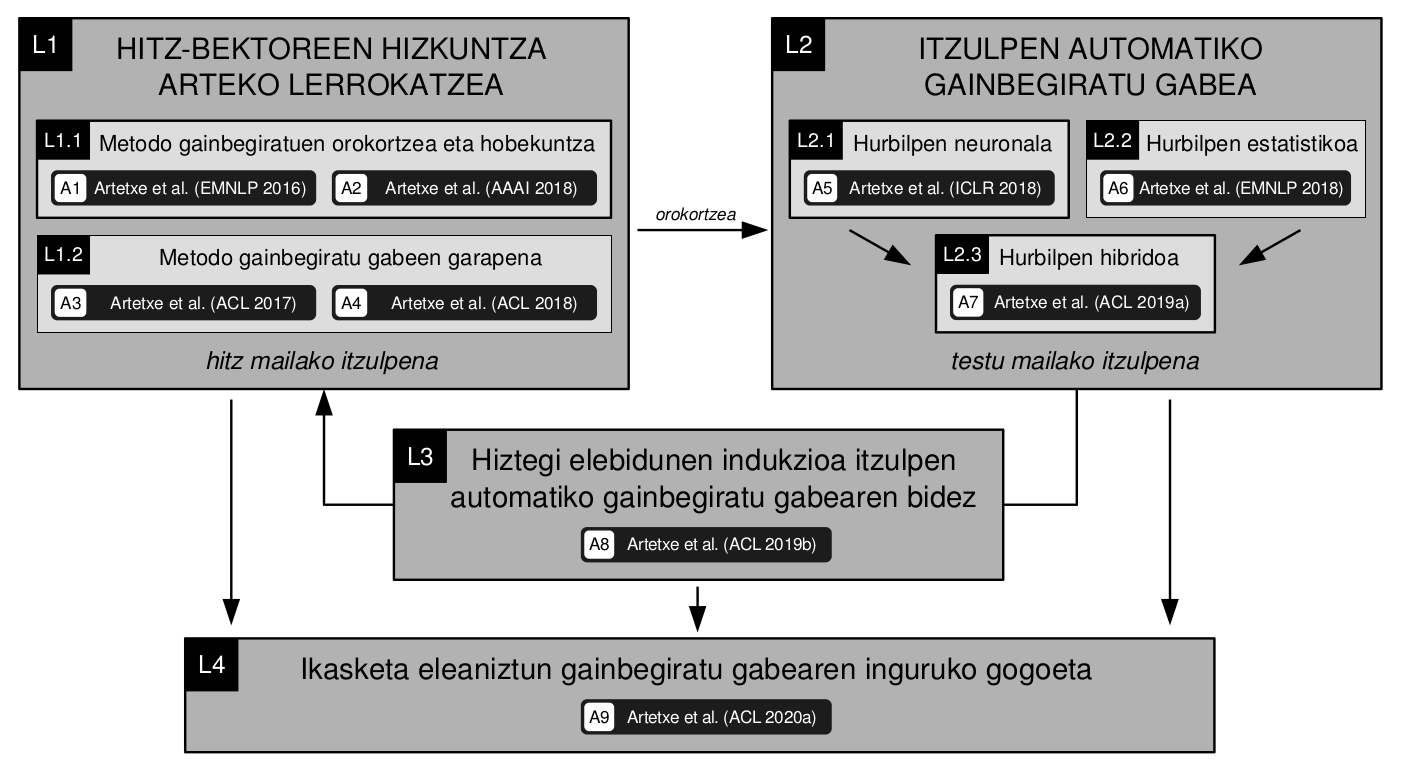
Title:  Unsupervised Machine Translation Unsupervised Machine Translation
/ Itzulpen automatiko gainbegiratu gabea
Non: Teleconference: https://eu.bbcollab.com/guest/b22b606d9ae74bc5b3e067821c897617
Faculty of informatics (UPV/EHU) Ada Lovelace room
Date: July 29, 2020, Wednesday, 11:00
Author: Mikel Artetxe Zurutuza
Supervisors: Eneko Agirre & Gorka Labaka
Languages: Basque (motivation, state of the art) and English (second half, papers, conclusions, ~11:30…)
Abstract:
The advent of neural sequence-to-sequence models has led to impressive progress in machine translation, with large improvements in standard benchmarks and the first solid claims of human parity in certain settings. Nevertheless, existing systems require strong supervision in the form of parallel corpora, typically consisting of several million sentence pairs. Such a requirement greatly departs from the way in which humans acquire language, and poses a major practical problem for the vast majority of low-resource
language pairs.
The goal of this thesis is to remove the dependency on parallel data altogether, relying on nothing but monolingual corpora to train unsupervised machine translation systems. For that purpose, our approach first aligns separately trained word representations in
different languages based on their structural similarity, and uses them to initialize either a neural or a statistical machine translation system, which is further trained through back-translation.
Mikel Artetxe publications related to his PhD work:
- Mikel Artetxe, Sebastian Ruder, Dani Yogatama, Gorka Labaka, Eneko Agirre (2020)
- Mikel Artetxe, Gorka Labaka, Eneko Agirre (2019)
Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 5002-5007.
- Mikel Artetxe, Gorka Labaka, Eneko Agirre (2019)
- Mikel Artetxe, Gorka Labaka, Eneko Agirre (2018)
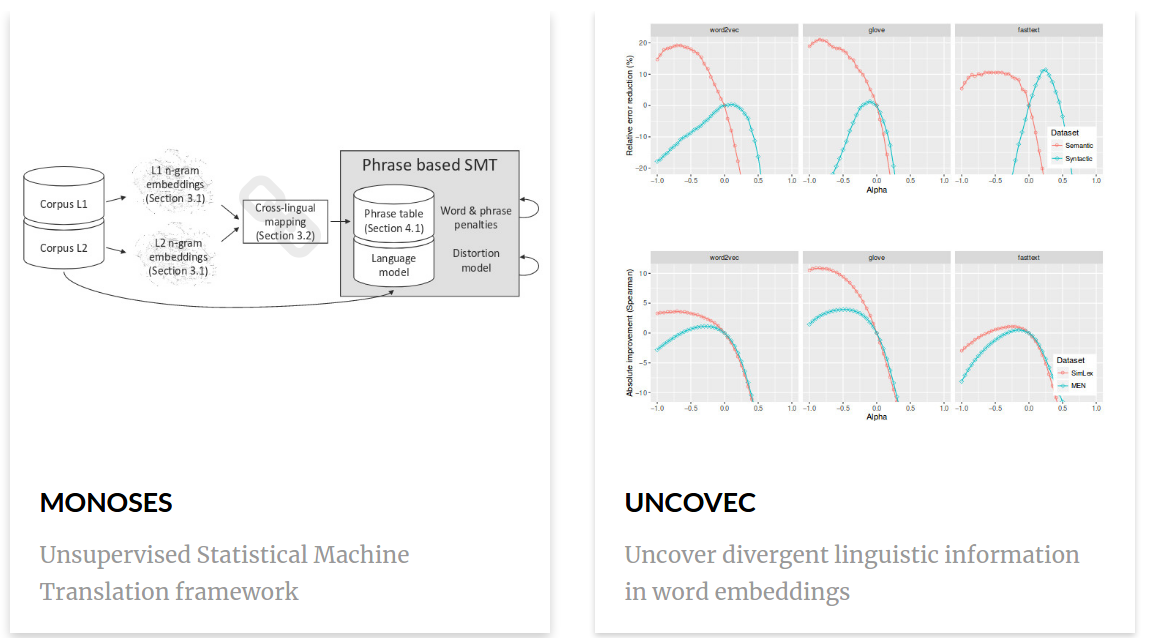
Unsupervised Statistical Machine Translation
In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 3632–3642, Brussels, Belgium, October-November. Association for Computational Linguistics.
- Mikel Artetxe, Gorka Labaka, Eneko Agirre (2018)
- Mikel Artetxe, Gorka Labaka, Eneko Agirre, Kyunghyun Cho (2018)
- Mikel Artetxe, Gorka Labaka, Eneko Agirre (2018)
Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence (AAAI-18) pages 5012-5019.
- Mikel Artetxe, Gorka Labaka, Eneko Agirre (2017)
- Mikel Artetxe, Gorka Labaka, Eneko Agirre (2016)
The three systems presented by IXA Group (HiTZ center) to the competition CAPITEL@IberLEF2020 have ranked first in Sub-task 1 (Named Entity Recognition and Classification in Spanish News Articles). The systems were developed by Rodrigo Agerri with the help of German Rigau, Ander Barrena and Jon Ander Campos.
Zorionak, congratulations to Rodrigo and all the team!
   

Within the framework of the PlanTL, the Royal Spanish Academy (RAE) and the Secretariat of State for Digital Advancement (SEAD) of the Ministry of Economy signed an agreement for developing a linguistically annotated corpus of Spanish news articles, aimed at expanding the language resource infrastructure for the Spanish language. The name of such corpus is CAPITEL (Corpus del Plan de Impulso a las Tecnologías del Lenguaje}, and is composed of contemporary news articles thanks to agreements with a number of news media providers. CAPITEL has three levels of linguistic annotation: morphosyntactic (with lemmas and Universal Dependencies-style POS tags and features), syntactic (following Universal Dependencies v2), and named entities.
The linguistic annotation of a subset of the CAPITEL corpus has been revised using a machine-annotation-followed-by-human-revision procedure. Manual revision has been carried out by a team of graduated linguists using the Annotation Guidelines created specifically for CAPITEL. The named entity and syntactic layers of revised annotations comprise about 1 million words for the former, and roughly 250,000 for the latter.
Due to the size of the corpus and the nature of the annotations, they proposed two IberLEF sub-tasks under the more general, umbrella task of CAPITEL @ IberLEF 2020, where they used the revised subset of the CAPITEL corpus in two challenges, namely:
(1) Named Entity Recognition and Classification and
(2) Universal Dependency Parsing.
 Oscar Sainz and Edgar Andrés, students of the HAP-LAP master, obtained an excellent result in the eHealth-2020 challenge presented with professors Oier Lopez de Lacalle and Aitziber Atutxa. Their team (IXA-NER-RE) has been “champion” in the Relational Extraction sub-task. Oscar Sainz and Edgar Andrés, students of the HAP-LAP master, obtained an excellent result in the eHealth-2020 challenge presented with professors Oier Lopez de Lacalle and Aitziber Atutxa. Their team (IXA-NER-RE) has been “champion” in the Relational Extraction sub-task.
Although their main objective was participation only in the Relation Extraction subtask, they also presented tiny systems in the other two subtasks (Entity Recognition and Alternative Domain) and so their system was fourth in the main evaluation.
ZORIONAK, CONGRATULATIONS!
You have done a good job!
The results can be consulted here:
https://knowledge-learning.github.io/ehealthkd-2020/results
 IXA-NER-RE was the “champion” in “Relation Extraction” subtask
|
|