Etiam pulvinar consectetur dolor sed malesuada. Ut convallis
euismod dolor nec pretium. Nunc ut tristique massa.
Nam sodales mi vitae dolor ullamcorper et vulputate enim accumsan.
Morbi orci magna, tincidunt vitae molestie nec, molestie at mi. Nulla nulla lorem,
suscipit in posuere in, interdum non magna.
I’m interested in getting insights from data by applying natural language processing, machine learning and statistical analyses. Ideally, those insights can then be turned into useful applications or facilitate higher level decisions.
Together with our software engineers I take care of our NLP capabilities: We work on improving and maintaining a highly flexible and scalable pipeline that is geared towards aspect-based sentiment analysis (and more in the future). Extracting knowledge from a large number of natural language texts allows us to understand our domain better and enhance the experience for our users.
Our technology stack includes:
– Python and Java
– R for analysis
– AWS for infrastructure
Ixa Group is an institutional member in the European Association of Machine Translation (EAMT) since 2012, the organization that serves the growing community of people interested in MT and translation tools, including users, developers, and researchers of this increasingly viable technology. Now we have pubished a new a page about IXA Group inside EAMT’s website.
The EAMT is one of three regional associations of the International Association for Machine Translation (IAMT). Its sister organizations are the Association for Machine Translation in the Americas (AMTA) and the Asia-Pacific Association for Machine Translation (AAMT).
Among other activities, the EAMT organizes the bi-annual MT Summit and the annual EAMT conferences, maintains the MT-List mailing list, and compiles listings of companies and products which are distributed free or at nominal cost to its members (Compendium of Translation Software)
The current 15 corporate and institutional members are the following:
Eguna / Date: maiatzaren 17a / May 17th Lekua / Place: Ada Lovelace aretoa / Ada Lovelace room
11:00
Adverse Drug Reaction event extraction on Electronic Health Records written in Spanish. Egilea / Author: Sara Santiso González Tutoreak / Supervirors: Alicia Pérez eta Arantza Casillas Epaimahaia: Eva Navas, Montse Maritxalar Arantza Casillas
11:45
Distributional Semantics and Machine Learning for Statistical Machine Translation Egilea / Author: Mikel Artetxe Zurutuza Tutoreak / Supervirors: Eneko Agirre eta Gorka Labaka Epaimahaia: Eva Navas, Montse Maritxalar, Gorka Labaka
Can language technology be helpful? Of course!!
Which tools can I use to communicate with refugees and help them?
We suggest some tools in this website.
Our aim is to give you an overview of the technology you can use with syrian refugees. English
Zertan lagun diezagukete hizkuntza-teknologiek?
Zein tresna/baliabide erabil ditzaket errefuxiatuekin komunikatzeko eta laguntzeko?
Atari honetan Siriako errefuxiatuekin erabil daitezkeen tresna batzuk proposatzen ditugu. Basque
¿En qué nos pueden ayudar las tecnologías del lenguaje?
¿Con qué recursos puedo comunicarme con los refugiados y ayudarles?
En esta página recomendamos algunos recursos disponibles que pueden resultar útiles con los refugiados sirios. Spanish
هل يمكن للتقنيات التي تم تطويرها في مجال اللغات أن تكون مفيدة لنا؟ الجواب هو طبعًا وبدون أي شك!ما هي الأدوات التي يمكن أن أستخدمها للتواصل مع اللاجئين ومساعدتهم؟نقترح في هذا الموقع بعض الأدوات المفيدة وهدفنا هو أن نعطيك لمحة عامة عن التقنيات والأدوات المتوفرة التي يمكنك استخدامها للتواصل مع اللاجئين السوريين
Donostia / San Sebastian 2016 European Capital of Culture represents an enormous opportunity to turn the focus on culture and dialogue as the roads towards improved coexistence. Thus, Donostia / San Sebastian aims to become a benchmark in the sphere of creative processes and culture.
Inside the programme, we are organising Codefest: Coding for Language Communities event, that will take place from 4th to 8th of July 2016 in Donostia / San Sebastián.
Codefest summer-lab, aims to revitalise resource scarce languages by providing them with effective tools for electronic communication and by teaching their communities how to use them. http://dss2016.eu/en/dss2016eu/voices/codefest
This one-week long hands-on course will give participants the opportunity to become acquainted with the latest language-based technologies and to develop different apps based on them. Partakers will work in a multidisciplinary coding bee that will team up linguists, software-engineers and students. http://dss2016.eu/en/dss2016eu/voices/codefest/project-proposals-codefest
Registration and Important Dates
Registration to attend Codefest is now open. You can register online and you will receive information about the payment procedure. If you are staying in Donostia – San Sebastian we will also collect information to arrange your accommodation.
Fees
• Basic registration (5 day participation, official dinner, welcome bag): 40€.
• Full registration (5 day participation, accommodation, 6 nights in a double room, official dinner, welcome bag): 260€.
• Full + Wikipedia edit a thon ( 5 day Codefest participation, 1 day Wikipedia edit a thon, accommodation, 7 nights in a double room, official dinner, welcome bag): 260€.
Healthcare has many challenges in form of monitoring and predicting adverse events as healthcare associated infections or adverse drug events. When and how many have occurred, how can one predict them? This talk will describe the research carried out at the Clinical text mining group at DSV/Stockholm University and the future research that will be carried out. Topics are detection of symptoms, diseases, body parts and drugs from Swedish electronic patient records, including deciding on the certainty of a symptom or disease and detecting adverse (drug) events. Current and future research are detecting early symptoms of cancer and de-identification of electronic patient records for secondary use. An overview of other researchers and groups in Scandinavia and Europe will be presented.
Curriculum Vitae:
Hercules Dalianis, born 20 July 1959, Dalianis is a professor in Computer and Systems Sciences at Stockholm University. Dalianis graduated in 1984 at KTH in Electrotechnical Engineering, (Civilingenjör), and received his PhD/Teknologie doctor) at KTH 1996. Dalianis was post doc researcher at University of Southern California/ISI in Los Angeles 1997-98. Dalianis was also post doc researcher (forskarassistent) at NADA KTH 1999-2003, moreover Dalianis held a three year guest professorship at CST, University of Copenhagen during 2002-2005, founded by Norfa, the Nordic council. Dalianis founded Euroling AB in year 2000. Euroling AB develops and delivers the web and intranet search engine SiteSeeker to over 350 customers, mostly Swedish governmental organisations. Dalianis works in the interface between industry and university and with the aim to make research results useful for society. Dalianis has specialized in the area of human language technology, to make computer to understand and process human language text, but also to make a computer to produce text automatically. Currently Dalianis is working in the area of clinical text mining with the aim to improve healthcare in form of better electronic patient record systems, presentation of the patient records and extraction of valuable information both for clinical researchers but also for lay persons as for example patients.
Eneko Agirrehas been awarded with aGoogle Research Awardafter its annual open call for proposals on computer science and related topics, including machine learning, speech recognition, natural language processing, and computational neuroscience. Google received 950 proposals covering 55 countries and over 350 universities, and decided to fund 151 projects, 10 of then related to Natural Language Processing.
Eneko will expend the $50.000 prize in research on “Learning Interlingual Representations of Words and Concepts.”. In the field of language processing Eneko is one of the 10 researchers awarded by Google. In addition to Eneko,alsothey have been awardedresearchers atuniversities likeHarvard, Berkeley,Edinburgh orWashington.
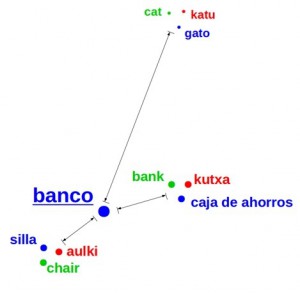
Eneko Agirre: “The goal of this basic research is the interlingual representation of the meaning of words, ie, knowing automatically when the meanings of two words are related in a language or in different languages. It would be like having a special dictionary to know which words have similar meanings. For example, knowing that the meaning of the word ‘banco‘ in Spanish is similar to ‘caja de ahorros‘ (‘savings bank’) and ‘silla‘ (chair’), depending on the word sense, but not to words like ‘cat‘ or ‘Monday‘. We visualize the distance between different senses of a word, and we can thus represent the senses of ‘banco‘, one that resembles ‘savings bank‘ and the other sense similar to ‘chair‘. Our proposal is able to represent the meanings of words from several languages in the same space, which allows us to know that a sense of ‘banco‘ is similar to ‘bank‘ and ‘kutxa‘ in English and Basque, respectively, and that the other sense of ‘banco’ is similar to ‘chair‘ and ‘aulki‘, but none of the two meanings are similar to ‘cat‘ or ‘katu‘”
Last week, Eneko Agirre was awarded with a Google Research Awards: Fall 2015 after its annual open call for proposals on computer science and related topics including machine learning, speech recognition, natural language processing, and computational neuroscience. Google received 950 proposals covering 55 countries and over 350 universities, and decided to fund 151 projects, ten of then related to Natural Language Processing.
Eneko will expend the $50.000 prize in research on “Learning Interlingual Representations of Words and Concepts.”

 Talk: Big Data and NLP at Trivago
Talk: Big Data and NLP at Trivago Ixa Group is an institutional member in the
Ixa Group is an institutional member in the 



 Talk: Clinical text mining at Stockholm University and at other research groups in Europe.
Talk: Clinical text mining at Stockholm University and at other research groups in Europe.