
Last week Google published in its Research Blog a new public resource, a dictionary for linking words to entities and ideas, comprising 7,560,141 concepts and 175,100,788 unique text strings. Valentin Spitkovsky and Peter Norvig hope it will assist research on moving from words to meaning — from turning search queries into relevant results and suggesting targeted keywords for advertisers —, in information retrieval, and in natural language processing.

Partial view of this post on the Google's Research blog
Parts of this work are descended from an earlier collaboration between University of Basque Country’s Ixa Group‘s Eneko Agirre and Stanford’s NLP Group, including Eric Yeh, presently of SRI International, and the Ph.D. advisors, Christopher D. Manning and Daniel Jurafsky.
The data set contains triples, each consisting of (i) text, a short, raw natural language string; (ii) url, a related concept, represented by an English Wikipedia article’s canonical location; and (iii) count, an integer indicating the number of times text has been observed connected with the concept’s url. Our database thus includes weights that measure degrees of association.
The authors hope that this release will fuel numerous creative applications that haven’t been previously thought of!
For technical details, see Google’s Research Blog, the paper they have recently presented at LREC 2012, or the README file accompanying the data.
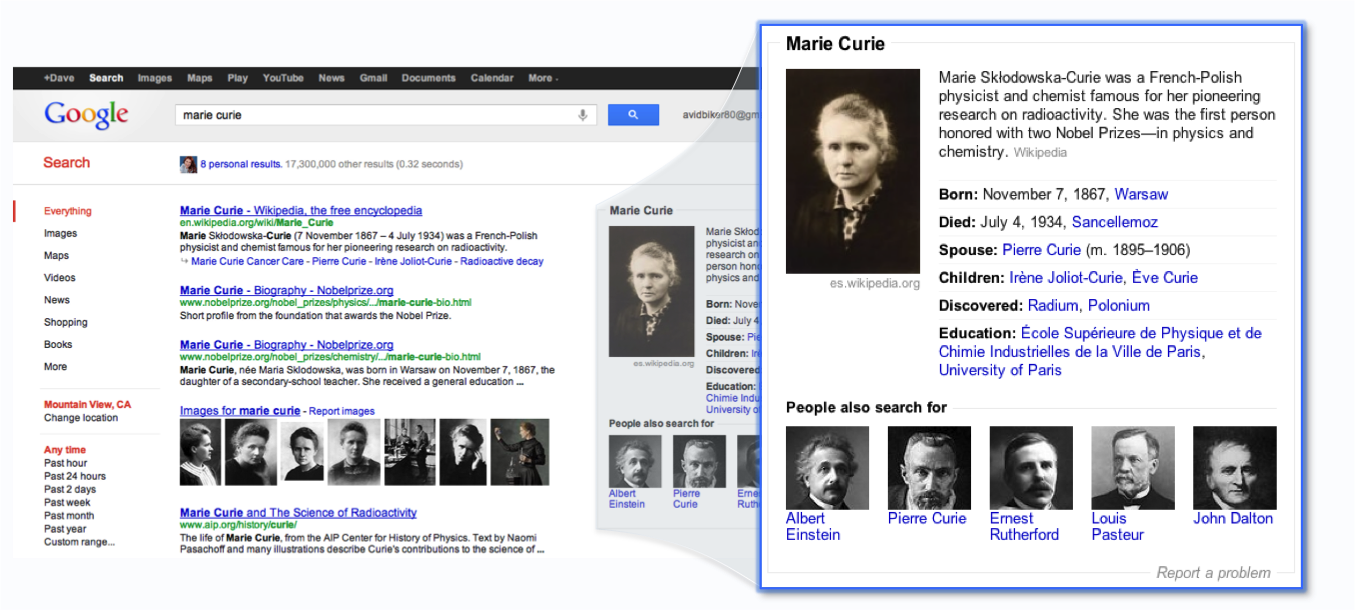
This resource might be linked to the recently launched Knowledge Graph, included in the English version of Google. The knowledge graph detects people, organisations and events related to the search query, and shows rich related information in the right hand side. For instance, this would be what we see if we search for Marie Curie:
[…] Google Research publishes an innovative concept dictionary, descended from collaboration with Ixa Gr… […]